Visual Tracking with THOR
Visual object tracking is a fundamental problem in computer vision. The goal is to follow the movements of an object throughout an image sequence. Generally, we do not have any information about the object, like its type (e.g., a cup) or a nice and clean CAD model. In the beginning, we get a bounding box around the object, which is drawn manually or given by an object detector, and then we need to keep track of the object throughout the sequence.
This task is challenging because, during the sequence, the lighting can drastically vary, the object could be occluded, or similar-looking objects could appear and distract our tracker. We are especially interested in object tracking since it is crucial for robotics applications, see some examples below.
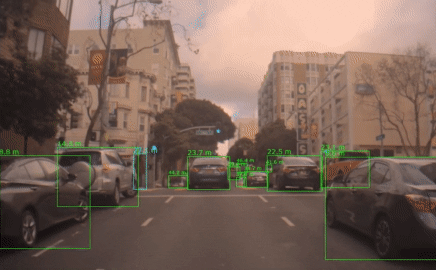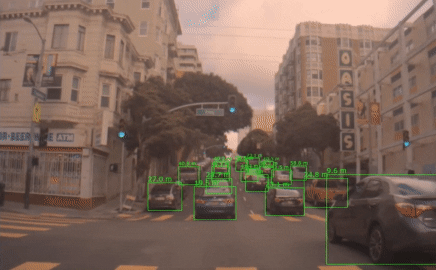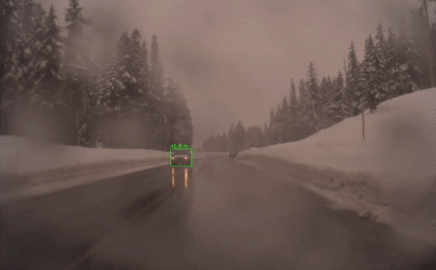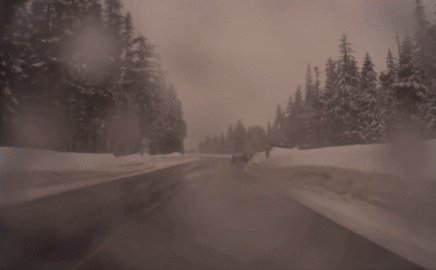

A common way to solve this problem is to do template matching. Given the first bounding box, we keep the patch inside of the box as a template. In the following frames, we match this template with the new image and compute the new bounding box. Siamese neural networks are especially effective to do this matching. Popular real-time capable trackers are SiamFC and SiamRPN.
Current challenges
The research community made significant improvements in visual object tracking, especially with the help of neural networks that can learn a very expressive feature space for the matching. However, current state-of-the-art approaches rely heavily on the assumption that the first template is all we need for robust object tracking. This assumption can prove to be problematic:
Such failure is a big problem. Imagine a robot loading a dishwasher, and while doing so, the robot would get confused because the appearance of the plates changes too much when moving them.
Well, there is an obvious and easy solution: use multiple templates! The reason why state-of-the-art trackers don’t do this is that using more than one template introduces a plethora of problems. There are two main problems. The first one is to determine if the current image crop (the pixels inside of the predicted bounding box) is also a good template. The second one is drift – the tracker could lose the object and start using templates that do not show the object, and the performance goes downhill from there.
Can we still make multiple template tracking work?
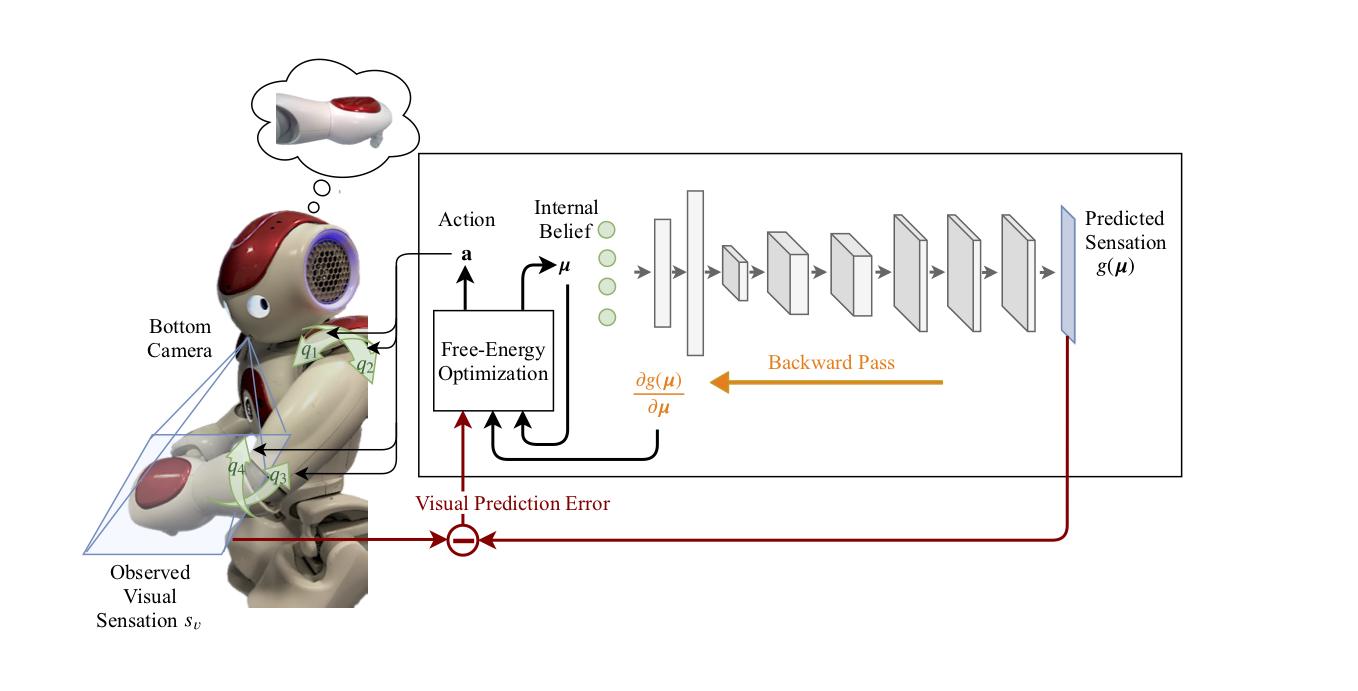
We made steps towards this aim with our recent work called THOR (short for Tracking Holistic Object Representations, possibly inspired by a certain Marvel character). Our objective was to develop an approach that can be plugged on top of any tracker (that is, any tracker that computes a similarity measure in feature space based on an inner-product operation) to improve its performance and robustness.
But instead of training a new network on a big dataset, we want to squeeze out as much as we possibly can of the information accumulated during tracking. Therefore we assume one thing: we only should keep the templates if they contain additional information – they should be as diverse as possible.
How do we get diverse templates?
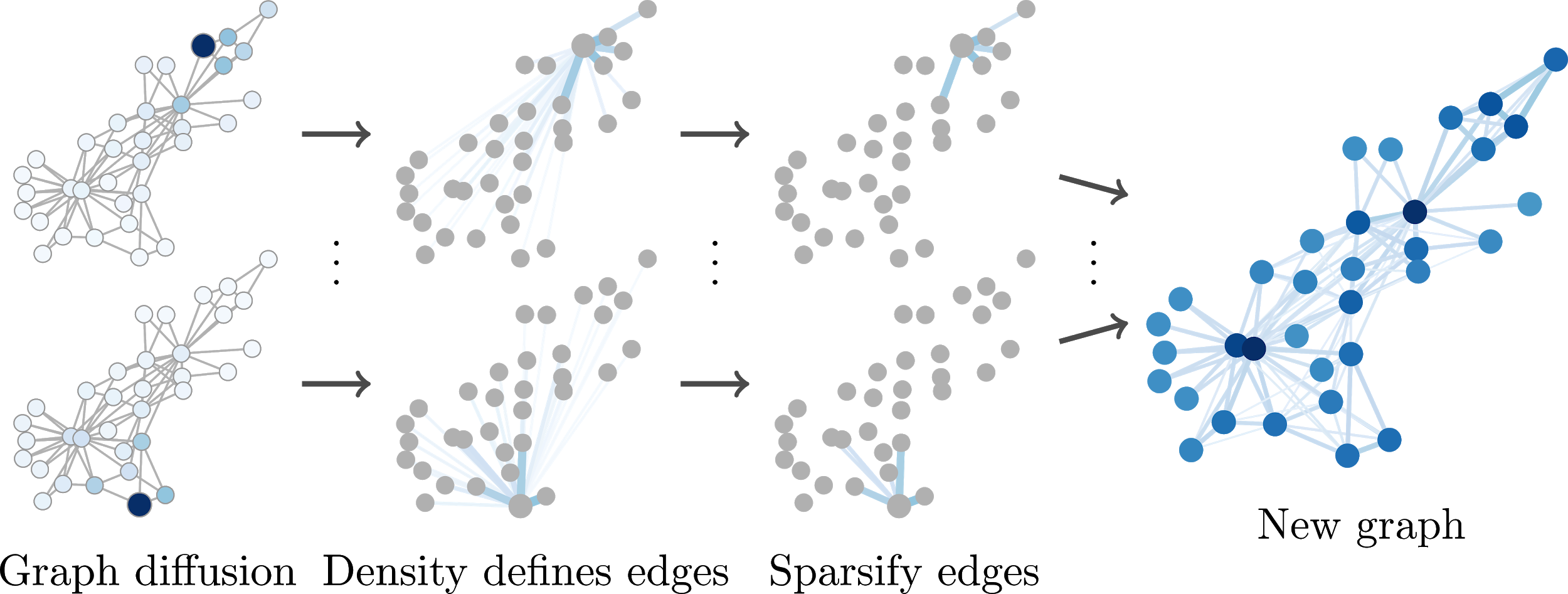
The siamese network was trained to learn a feature space that is used to compute similarities. We leverage this property, but not do tracking, rather to find out how similar two templates are.
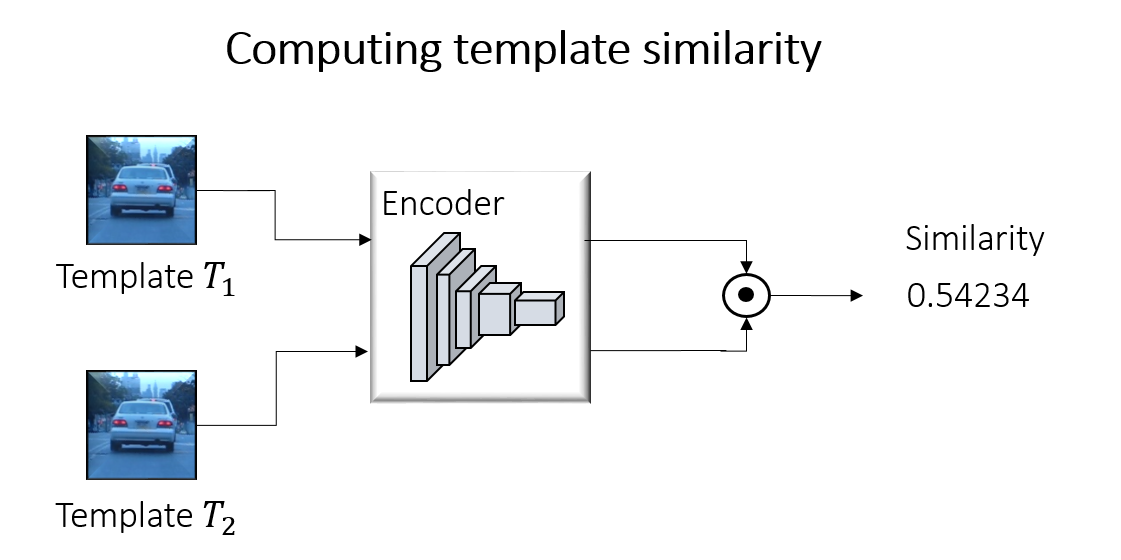
If we compute the similarity of all templates $f_i$ with each other, we can construct a Gram matrix:
Now, to increase diversity, we need to increase the volume that the feature vectors $f_i$ span in the feature space – the bigger the volume, the higher the diversity. A nice property of the Gram matrix is that its determinant is proportional to this spanned volume. So, maximizing the determinant, maximizes the volume:
where $\Gamma$ is the spanned volume. So, when we receive a new template, we check if it increases the determinant. If that is the case, we include this template in our memory.

We do all these calculations in the Long-term module (LTM), which is the heart piece of THOR. To make it work even better, we introduce other, simpler concepts like a short-term module that handles abrupt movements and occlusion.
Experiments
So, let’s try the previous setting again:
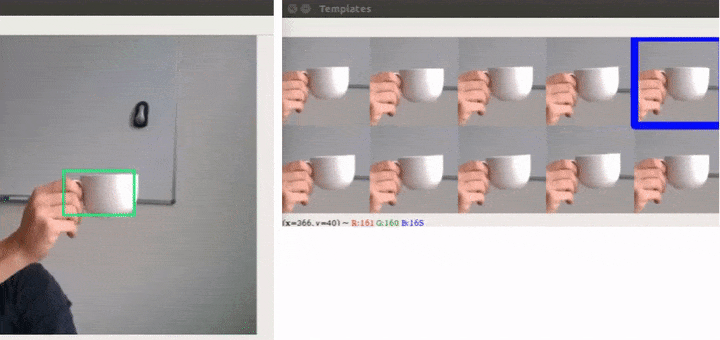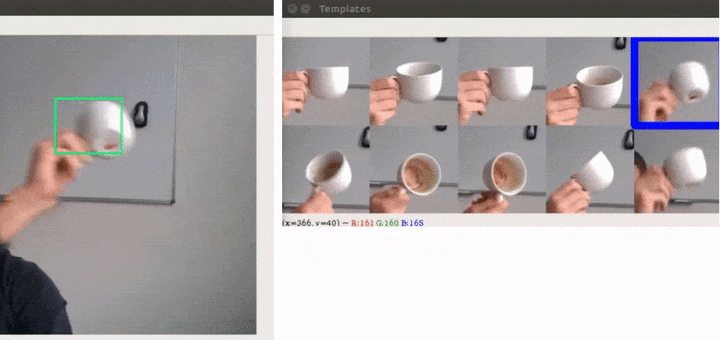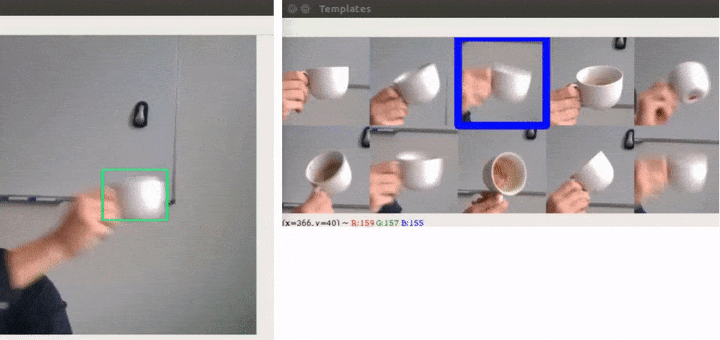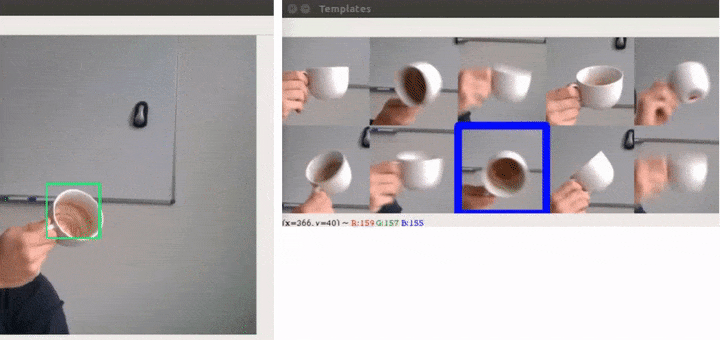
Not only are we able to handle the problem that we set out to solve, but we also plugged THOR on top of 3 different trackers and were able to improve all of them on commonly used benchmarks. At the time of publishing, THOR even achieved state-of-the-art on VOT benchmark.
Speed is especially important for robotics applications, but more templates mean more computation for each frame, therefore generally slowing the tracking down. However, we can do all the additional calculations in parallel, so we don’t slow the tracker down much. We achieved state-of-the-art performance while being 3 times faster than the previous best approach since we get away with using smaller simpler network.

A nice side effect: recently, researchers added additional output branches to the tracking networks that also predicts an object mask. We can plug THOR on top of such trackers without any modification.

More Info
If you got interested in our work and want to learn more, check out the project page and the paper. The code is open-source. We were very honored to receive the Best Science Paper Award at the British Machine Vision Conference 2019 for this work.
@inproceedings{Sauer2019BMVC,
author={Sauer, Axel and Aljalbout, Elie and Haddadin, Sami},
title={Tracking Holistic Object Representations},
booktitle={British Machine Vision Conference (BMVC)},
year={2019}
}